数据集划分K折交叉验证KFold
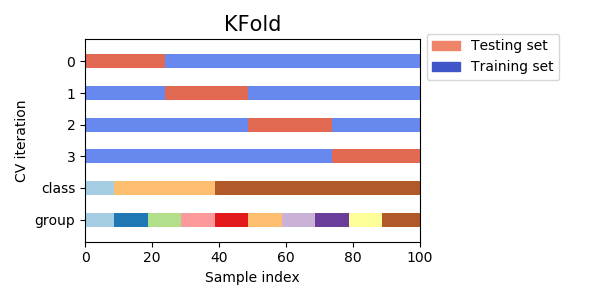
- 将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个自己有m/k个训练样例,相应的子集为{s1,s2,...,sk}
- 每次从分好的子集里面,拿出一个作为测试集,其他k-1个作为训练集
- 在k-1个训练集上训练出学习器模型
- 把这个模型放到测试集上,得到分类率的平均值,作为该模型或者假设函数的真实分类率
这个方法充分利用了所以样本,但计算比较繁琐,需要训练k次,测试k次

函数
class sklearn.model_selection.KFold(n_splits=5,
*,
shuffle=False,
random_state=None)
参数:
n_splits:表示划分几等份
shuffle:在每次划分时,是否进行洗牌
- 若为Falses时,其效果等同于random_state等于整数,每次划分的结果相同
- 若为True时,每次划分的结果都不一样,表示经过洗牌,随机取样的
random_state:随机种子数
Methods
get_n_splits(X=None, y=None, groups=None):获取参数n_splits的值split(X, y=None, groups=None):将数据集划分成训练集和测试集,返回索引生成器
Examples
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4])
>>> kf = KFold(n_splits=2)
>>> kf.get_n_splits(X)
2
>>> print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
# kf.split(X) 获取划分后的索引
>>> for train_index, test_index in kf.split(X):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]