主成分分析PCA
维度指的是样本的数量或特征的数量,一般无特别说明,指的都是特征的数 量 。
降维算法中的”降维“,指的是降低特征矩阵中特征的数量。
PCA
在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或者有一些特征带有的信息和其他一些特征是重复的(比如一些特征可能会线性相关)。我们希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵 。
在降维中,PCA 使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。
Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值,xhat代表这一列样本的均值。
class sklearn.decomposition.PCA (n_components=None,
copy=True,
whiten=False,
svd_solver=’auto’,
tol=0.0,
iterated_power=’auto’,
random_state=None
)
思考:PCA和特征选择技术都是特征工程的一部分,它们有什么不同?
特征工程中有三种方式:特征提取,特征创造和特征选择。仔细观察上面的降维例子和上周我们讲解过的特征 选择,你发现有什么不同了吗?
特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,我们依然知道这个特 征在原数据的哪个位置,代表着原数据上的什么含义。
而 PCA,是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某 些方式组合起来的新特征。通常来说,在新的特征矩阵生成之前,我们无法知晓 PCA 都建立了怎样的新特征向 量,新特征矩阵生成之后也不具有可读性,我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而 来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了。以 PCA 为代表的降维算法因此是 特征创造(feature creation,或feature construction)的一种。
可以想见,PCA 一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标 签之间的关系不具有意义。在线性回归模型中,我们使用特征选择
重要参数
n_components
n_components 是我们降维后需要的维度,即降维后需要保留的特征数量 。
选择最好的n_components:累积可解释方差贡献率曲线 。
当参数n_components中不填写任何值,则默认返回min(X.shape)个特征,一般来说,样本量都会大于特征数目,所以什么都不填就相当于转换了新特征空间,但没有减少特征的个数。一般来说,不会使用这种输入方式。但我们却可以使用这种输入方式来画出累计可解释方差贡献率曲线,以此选择最好的n_components的整数取值。累积可解释方差贡献率曲线是一条以降维后保留的特征个数为横坐标,降维后新特征矩阵捕捉到的可解释方差贡献率为纵坐标的曲线,能够帮助我们决定n_components最好的取值。
import numpy as np
pca_line = PCA().fit(X)
plt.plot([1,2,3,4],np.cumsum(pca_line.explained_variance_ratio_))
plt.xticks([1,2,3,4]) #这是为了限制坐标轴显示为整数
plt.xlabel("number of components after dimension reduction")
plt.ylabel("cumulative explained variance ratio")
plt.show()
最大似然估计自选超参数
除了输入整数,n_components还有哪些选择呢?数学大神Minka, T.P.在麻省理工学院媒体实验室做研究时找出了让PCA用最大似然估计(maximum likelihood
estimation)自选超参数的方法,输入mle 作为n_components的参数输入,就可以调用这种方法
pca_mle = PCA(n_components="mle")
pca_mle = pca_mle.fit(X)
X_mle = pca_mle.transform(X)
按信息量占比选超参数
输入[0,1]之间的浮点数,并且让参数 svd_solver =='full',表示希望降维后的总解释性方差占比大于n_components指定的百分比,即是说,希望保留百分之多少的信息量。比如说,如果我们希望保留97%的信息量,就可以输入n_components = 0.97,PCA会自动选出能够让保留的信息量超过97%的特征数量。
pca_f = PCA(n_components=0.97,svd_solver="full")
pca_f = pca_f.fit(X)
X_f = pca_f.transform(X)
pca_f.explained_variance_ratio_
svd_solver 与 random_state
参数svd_solver是在降维过程中,用来控制矩阵分解的一些细节的参数。有四种模式可选:auto, full, arpack,randomized,默认”auto"。
通常我们就选用auto,不必对这个参数纠结太多
重要属性
components_
explained_variance_
explained_variance_ratio_
PCA是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。通常来说,在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性,我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了
但是其实,在矩阵分解时,PCA是有目标的:在原有特征的基础上,找出能够让信息尽量聚集的新特征向量。在sklearn使用的PCA和SVD联合的降维方法中,这些新特征向量组成的新特征空间其实就是V(k,n)。当V(k,n)是数字时,我们无法判断V(k,n)和原有的特征究竟有着怎样千丝万缕的数学联系。但是,如果原特征矩阵是图像,V(k,n)这个空间矩阵也可以被可视化的话,我们就可以通过两张图来比较,就可以看出新特征空间究竟从原始数据里提取了什么重要的信息
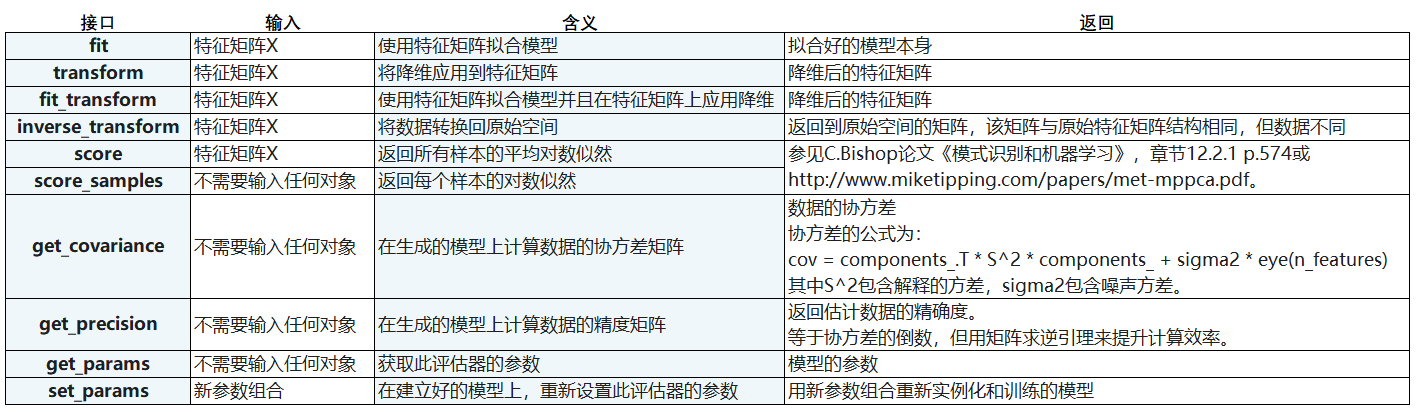
重要接口
inverse_transform
接口inverse_transform,可以将我们归一化,标准化,甚至做过哑变量的特征矩阵还原回原始数据中的特征矩阵 , 这几乎在向我们暗示,任何有inverse_transform这个接口的过程都是可逆的。PCA 应该也是如此。
PCA 参数列表



PCA 属性列表

PCA 接口列表