数据集的分布
当我们上手一个数据集时,往往第一件事就是了解每个变量是如何分布的。seaborn中检验一元分布和二元(维)分布。你也许会对如何对比一个变量在其他变量的不同水平下的分布有什么差异,在分类数据可视化教程中,你可以找到答案。
一元分布的可视化
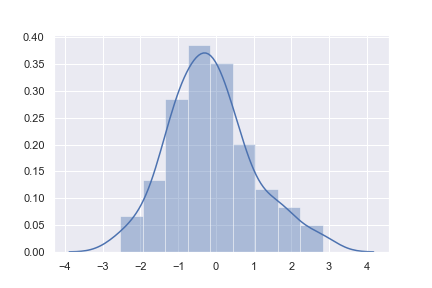
在seaborn中,查看单变量分布情况最方便的方法就是使用distplot()函数。默认情况下,它会画一个直方图,并且做一个核密度估计(KDE)
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
sns.set(color_codes=True)
x = np.random.normal(size=100)
sns.distplot(x)
直方图
直方图我们应该都很熟悉了,matplotlib中也有一个hist()函数来绘制直方图。直方图将数据划分到多个数据桶中,然后对每个桶中的样本进行计数,并将它们以长条的形式画出来。
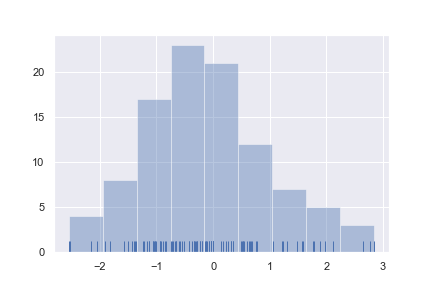
我们通过演示来理解这个过程:去掉密度曲线,并且加一个“地毯图”(rugplot)。地毯图会在每个观测值的位置添加一个垂直的线段小标记。我们可以使用rugplot()来仅仅绘制地毯图,不过它在distplot()中已经得到了支持:
# 高度和下方标记的密集度是成正比的
sns.distplot(x, kde=False, rug=True)
参数 bins
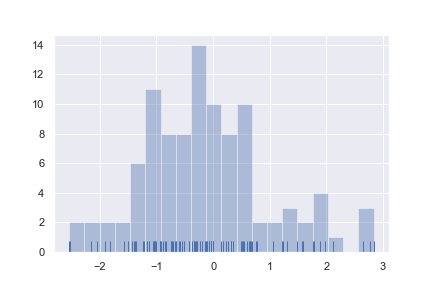
在绘制直方图时,最主要的选择就是指定数据桶的数量以及它们的边界。distplot()默认会用一条简单的规则来猜测多少个数据桶最合适,不过尝试更多或更少的分桶也许能帮助我们揭示数据的更多特性:
sns.distplot(x, bins=20, kde=False, rug=True)
核密度估计
我们对核密度估计可能不太熟悉,但是它在展示数据分布形状方面很有用。与直方图类似,KDE图用高度对观测值的密度进行编码:
sns.distplot(x, hist=False, rug=True)

相对于直方图,KDE图的绘制有更高的计算复杂度。在KDE的计算中,首先每个观测值会被替换为一条以该观测点为中心的正态曲线
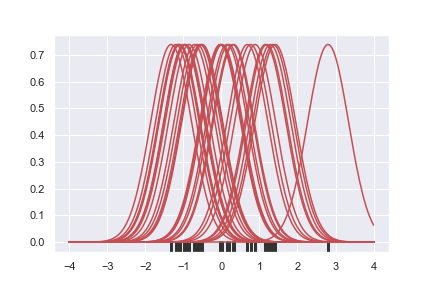
接下来,我们把所有的曲线都叠加起来,得到每个点上的密度。然后我们把最终的曲线正则化(归一化),这样曲线下方的面积加起来刚好是1

如果我们直接用kdeplot()函数,那我们会得到同样的结果。distplot()中集成了这个函数,但是当我们只想绘制密度估计图时,kdeplot()能提供更直接的接口以及更多的选项。
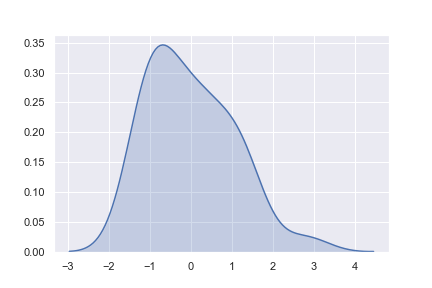
拟合指定的分布
可以使用distplot()将数据拟合到一个指定的分布形态,我们可以在视觉上评估它们有多接近:

二元分布可视化
将两个变量的联合分布形态可视化出来往往会很有用。在seaborn中,最简单的实现方式是使用jointplot()函数,它会生成多个面板,不仅展示了两个变量之间的关系,也在两个坐标轴上分别展示了每个变量的分布。
散点图
最常见的展示二元分布的方法是使用散点图,我们使用x、y两个坐标轴来定位每一个观测值。它类似于二维的地毯图。我么可以使用matplotlib中的plt.scatter()函数来绘制散点图,同时,jointplot()的默认绘制类型也是散点图。
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
sns.jointplot(x="x", y="y", data=df)
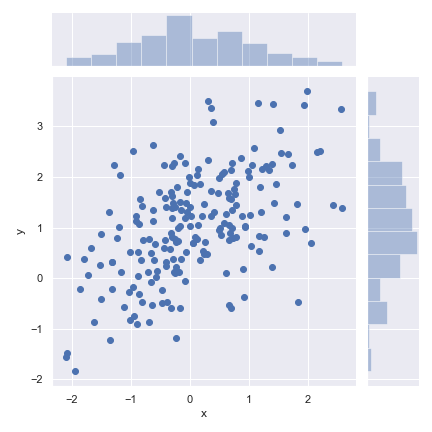
六边图
六边图(Hexbin),可以视为二维世界中的直方图,因为它展示了每个小六边形中观测点的数量。这种图在大数据集上表现最佳。我们使用matplotlib的plt.hexbin函数以及seaborn的jointplot(kind="hex")都可以绘制它。
x, y = np.random.multivariate_normal(mean, cov, 1000).T
with sns.axes_style("white"):
sns.jointplot(x=x, y=y, kind="hex", color="k")

核密度估计
核密度估计也适用于二元的情况。在seaborn中,这种图会以等高线的方式展示出来,我们可以用jointplot(kind="kde")来绘制它
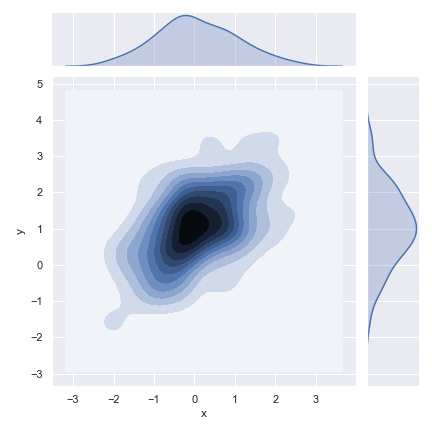
我们也可以直接使用kdeplot()来绘制二维的核密度估计图。这允许我们直接在某个指定的matplotlib坐标轴上(包括已存在的坐标轴体系)绘制这类图形。作为对比,在jointplot()中我们只能创建一个新的图来生成核密度估计图。
f, ax = plt.subplots(figsize=(6, 6))
sns.kdeplot(df.x, df.y, ax=ax)
sns.rugplot(df.x, color="g", ax=ax)
sns.rugplot(df.y, vertical=True, ax=ax)

jointplot()函数基于JointGrid对象来控制图形。我们可以直接使用JointGrid来获得更高的灵活性。jointplot()在绘制完成后会返回一个JointGrid对象,我们可以通过它来增加更多图层或者调整其他细节
g = sns.jointplot(x="x", y="y", data=df, kind="kde", color="m")
g.plot_joint(plt.scatter, c="w", s=30, linewidth=1, marker="+")
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels("$X$", "$Y$")

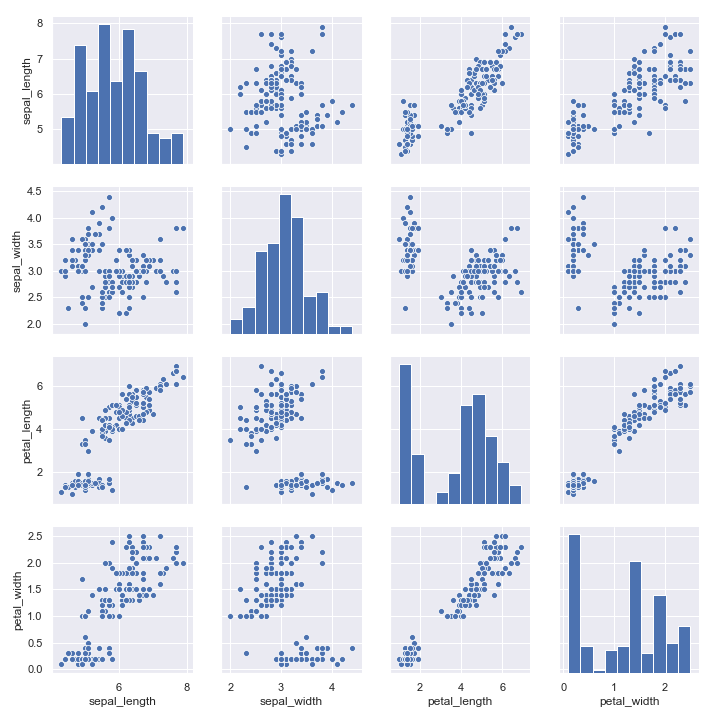
数据集中成对关系的可视化
成对关系的可视化是指在一个数据集的所有变量中,两两之间的关系。假如我们想要看多个变量中两两组合之间的联合分布情况,我们可以使用pairplot()函数,它会创建一个由多个坐标轴构成的矩阵,然后把两两之间(一般是DataFrame的列之间的组合)的关系分别绘制在不同的坐标轴上去。默认情况下,它还会将每个变量自己的分布情况画在对角线的位置:
iris = pd.read_csv("iris.csv")
sns.pairplot(iris)