seaborn.scatterplot
seaborn.scatterplot(x=None, y=None,
hue=None, style=None,
size=None, data=None,
palette=None, hue_order=None,
hue_norm=None, sizes=None,
size_order=None, size_norm=None,
markers=True, style_order=None,
x_bins=None, y_bins=None,
units=None, estimator=None,
ci=95, n_boot=1000,
alpha='auto',
x_jitter=None, y_jitter=None,
legend='brief', ax=None, **kwargs)
绘制几个语义分组的散点图。
数据的不同子集的 x 和 y 之间的关系可以用 hue, size, style 这三个参数来控制绘图属性。 这些参数控制用于识别不同子集的视觉语义信息,三种语义类型全部使用的话可以独立显示三个维度, 但是这种风格的绘图很难解释或者说没大部分时候什么效果。使用过多的语义信息 (例如:对同一个变量同时使用 hue 和 style)对作图来说是很有帮助同时也更容易理解。
阅读下面的教程可以 get 更多信息哦。
参数:
x, y: data 或是向量 data 里面的变量名字,可选择
输入数据的变量,必须是数字,可以直接传递数据或引用数据中的列
hue: data 或是向量 data 里面的变量名字,可选择
将产生不同大小的点的变量进行分组,可以是类别也可以是数字, 但是大小映射在后一种情况会有不同的表现
style: data 或是向量 data 里面的变量名字,可选择
将产生不同标记的点的变量进行分类,可以有一个数字类型,但是这个数字会被当作类别
data:DataFrame
Tidy (“long-form”) dataframe 它的每一列是一个变量,每一行是一个观测值
plaette : 调色板的名字、列表或字典,可选
用于不同 level 的 hue 变量的颜色,应该是可以被 color_palette() 执行的 something, 或者是一个可以对 matplotlib colors 映射 hue 级别的字典。
hue_order:列表,可选
对 hue 变量的级别的表象有特定的顺序,否则的话,顺序由 data 决定。当 hue 是数字的时候与它不相关
hue_norm:元组或标准化的对象,可选
当 hue 变量是数字的时候,应用于 hue 变量的色彩映射的数据单元中的标准化。如果是类别则不相关
sizes:列表,字典或元组,可选
当使用 size 的时候,用来决定如何选择 sizes 的一个对象。可以一直是一个包含 size 数值的列表, 或者是一个映射变量 size 级别到 sizes 的字典。当 size 是数字时,sizes 可以是包含 size 最大值 和最小值的元组,其他的值都会标准化到这个元组指定的范围
size_order:元组,可选
size 变量级别表现的特定顺序,否则顺序由 data 决定,当 size 变量是数字时不相关
size_norm:元组或标准化的对象,可选
当变量 size 是数字时,用于缩放绘图对象的数据单元中的标准化
makers:布尔型,列表或字典,可选
决定如何绘制不同级别 style 的标志符号。设置为 True 会使用默认的标志符号,或者通过一系列标志 或者一个字典映射 style 变量的级别到 markers。设置为 False 会绘制无标志的线。 Markers 在 matplotlib 中指定
style_order:列表,可选
对于 style 变量级别表象的特定顺序,否则由 data 决定,当 style 是数字时不相关
{x,y}_bins: 元组,矩阵或函数
暂时没有什么功能
units:{long_form_var}
分组特定的样本单元。使用时,将为每个具有适当的语义的单元绘制一根单独的线, 但不会添加任何图例条目。 当不需要确切的身份时,可用于显示实验重复的分布。 目前没啥作用
estimator:pandas 方法的名称,或者可调用的方法或者是 None,可选
聚类同一个 x 上多个观察值 y,如果是 None,所有的观察值都会绘制,目前暂无功能
ci:整型或 'sd' or None,可选
与估算器聚合时绘制的置信区间的大小。 “sd”表示绘制数据的标准偏差。 设置为 None 将跳过自举。 目前无功能。
n_boot:整型,可选
自举法的数量,用于计算区间的置信度,暂无功能
alpha:浮点型
设置点的不透明度
{x,y}_jitter:布尔或者浮点型
暂无功能
legend:“brief”, “full”, or False, 可选
绘制图例的方式。如果为“brief" 数字 hue 和 size 变量会代表一个样本,即便有不同的值 if "full", 每一个分组都有图例。if False 不绘制也不添加图例
ax:matplotlib 坐标轴,可选
绘制图像的坐标对象,否则使用当前坐标轴
kwargs:键值映射对
在绘制的时候其他的键会传递给 plt.scatter
返回值:ax:matplotlib 坐标轴
返回绘制所需的坐标
edgecolor 设置轮廓色:
edgecolor=None 五轮廓色
请参阅官方文档
用线显示两个变量之间的关系以强调连续性。绘制带有一个分类变量的散点图,排列点以显示值的分布。
例子
绘制一个两个变量的简单散点图:
import seaborn as sns; sns.set()
import matplotlib.pyplot as plt
tips = sns.load_dataset('tips')
ax = sns.scatterplot(x='total_bill',y='tip',data=tips)
通过其他的变量分组并且用不同的颜色展示分组
ax = sns.scatterplot(x='total_bill',y='tip',hue='time',data=tips)
通过不同的颜色和标记显示分组变量:
ax = sns.scatterplot(x='total_bill',y='tip',
hue='time',style='time',data=tips)
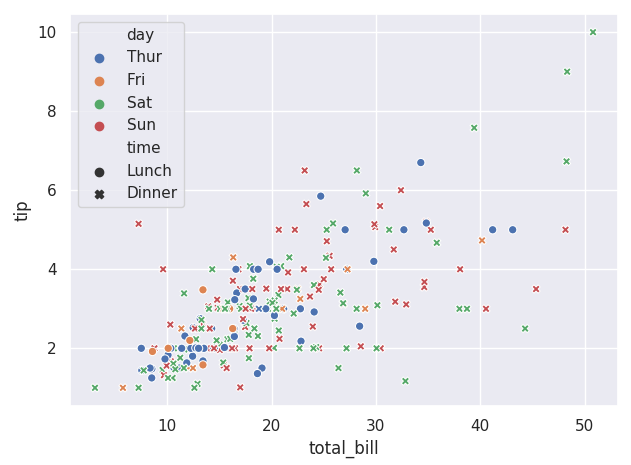
不同的颜色和标志显示两个不同的分组变量:
ax = sns.scatterplot(x='total_bill',y='tip',
hue='day',style='time',data=tips)
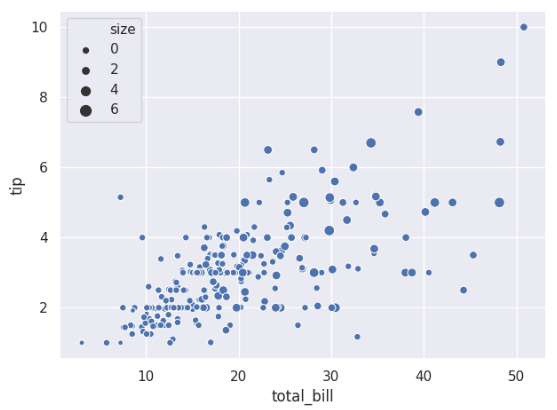
用不同大小的点显示一个变量的数量:
ax = sns.scatterplot(x='total_bill',y='tip', size='size',data=tips)
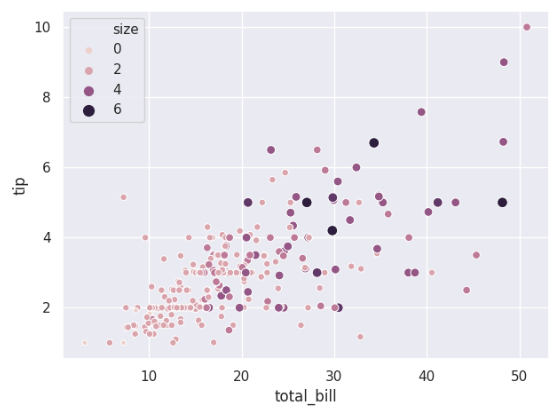
使用渐变的颜色显示变量的数量:
ax = sns.scatterplot(x='total_bill',y='tip',
hue='size', size='size',data=tips)
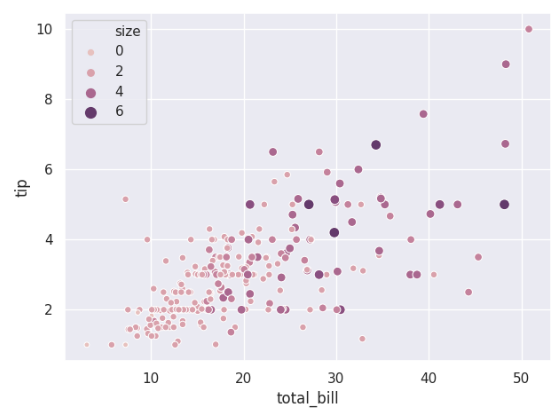
用一个不一样的渐变颜色映射:
cmap = sns.cubehelix_palette(dark=.3,light=.8,as_cmap=True)
ax = sns.scatterplot(x='total_bill',y='tip',
hue='size', size='size',palette=cmap,data=tips)
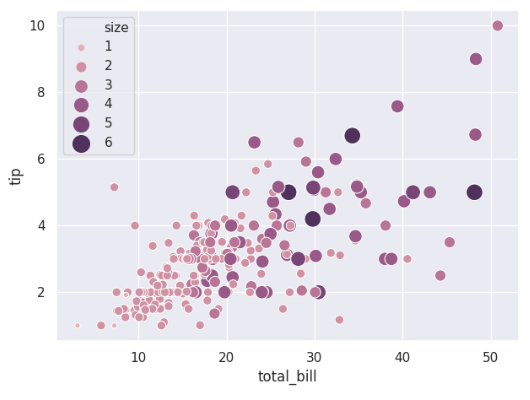
改变点大小的最小值和最大值并在图例中显示所有的尺寸:
cmap = sns.cubehelix_palette(dark=.3,light=.8,as_cmap=True)
ax = sns.scatterplot(x='total_bill',y='tip',
hue='size',size='size', sizes=(20,200),legend='full',palette=cmap,data=tips)
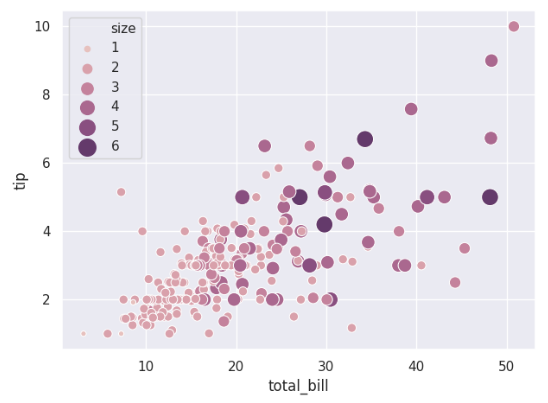
使用一个更小的颜色强度范围:
cmap = sns.cubehelix_palette(dark=.3,light=.8,as_cmap=True)
ax = sns.scatterplot(x='total_bill',y='tip',hue='size',size='size',
sizes=(20,200),hue_norm=(0,7), legend='full',data=tips)
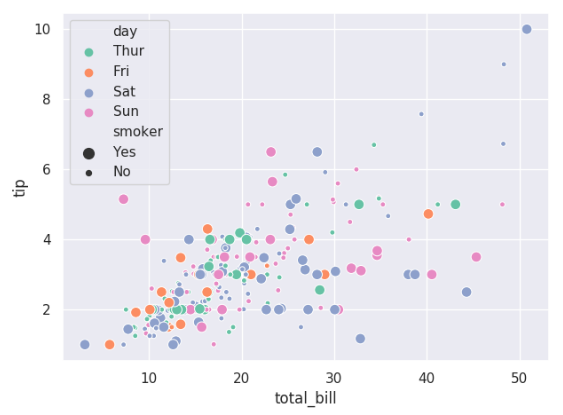
一个类别变量不同的大小,用不同的颜色:
ax = sns.scatterplot(x='total_bill',y='tip',hue='day',size='smoker',
palette='Set2',data=tips)
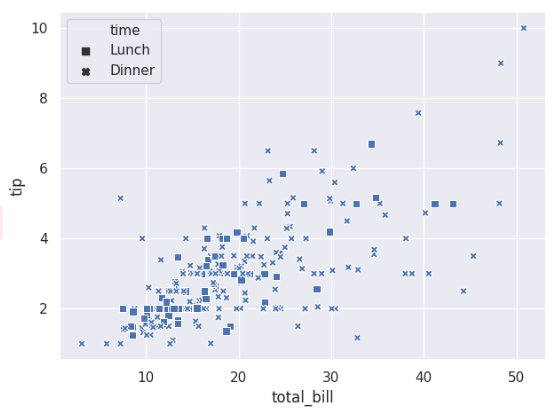
使用一些特定的标识:
markers = {'Lunch':'s','Dinner':'X'}
ax = sns.scatterplot(x='total_bill',y='tip',style='time',
markers=markers,data=tips)
使用 matplotlib 的参数控制绘制属性:
ax = sns.scatterplot(x='total_bill',y='tip',
s=100,color='.2',marker='+',data=tips)
使用 data 向量代替 data frame 名字:
iris = sns.load_dataset('iris')
ax = sns.scatterplot(x=iris.sepal_length,y=iris.sepal_width,
hue = iris.species,style=iris.species)
传递宽格式数据并根据其索引进行绘图:
import numpy as np, pandas as pd; plt.close("all")
index = pd.date_range('1 1 2000',periods=100,freq='m',name='date')
data = np.random.randn(100,4).cumsum(axis=0)
wide_df = pd.DataFrame(data,index,['a','b','c','d'])
print(wide_df.head())
ax = sns.scatterplot(data=wide_df)