CUME_DIST函数
CUME_DIST() 函数
CUME_DIST() 函数概述
CUME_DIST()是一个窗口函数,它返回一组值中值的累积分布。它表示值小于或等于行的值除以总行数的行数。
CUME_DIST()函数的返回值大于零且小于或等于1(0 CUME_DIST()<< = 1)。重复的列值接收相同的CUME_DIST()值。
以下显示了CUME_DIST()函数的语法:
CUME_DIST() OVER (
PARTITION BY expr, ...
ORDER BY expr [ASC | DESC], ...
)
在此语法中, PARTITION BY 子句将FROM子句返回的结果集划分为CUME_DIST()函数适用的分区。
ORDER BY子句指定每个分区中行的逻辑顺序,或者在PARTITION BY省略的情况下指定整个结果集。CUME_DIST()函数根据分区中的顺序计算每行的累积分布值。
CUME_DIST()函数的近似公式如下:
ROW_NUMBER() / total_rows
CUME_DIST() 函数示例
让我们创建一个以scores示例的一些示例数据命名的表:
CREATE TABLE scores
(
name VARCHAR(20) PRIMARY KEY,
score INT NOT NULL
);
INSERT INTO scores(name, score)
VALUES ('Smith', 81),
('Jones', 55),
('Williams', 55),
('Taylor', 62),
('Brown', 62),
('Davies', 84),
('Evans', 87),
('Wilson', 72),
('Thomas', 72),
('Johnson', 100);
查找结果集中分数的累积分布:
select name,
score,
row_number() over (order by score) row_num,
cume_dist() over (order by score) cume_dist_val
from scores;
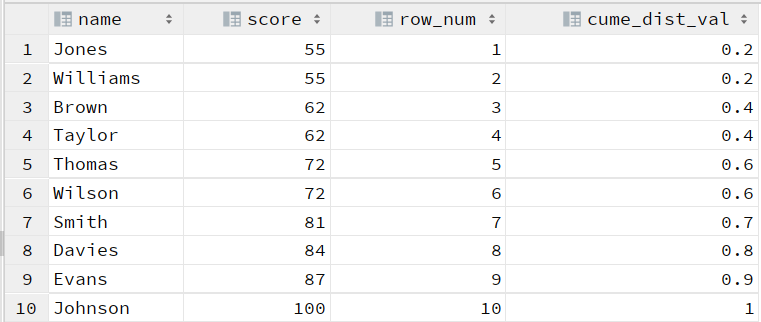
在此示例中,分数按从55到100的升序排序。请注意,ROW_NUMBER()添加了功能以供参考。
那么CUME_DIST()函数如何执行计算?
对于第一行,函数查找结果集中的行数,其值小于或等于55.结果为2.然后,CUME_DIST()函数将2除以总行数10:2/10。结果是0.2或20%。相同的逻辑应用于第二行。
对于第三行,函数查找值小于或等于62的行数。有四行。然后CUME_DIST()函数的结果是:4/10 = 0.4,即40%。
相同的计算逻辑应用于其余行。